Content negotiation in OGC API
This week I took part in the 19th OGC API codesprint, in Brussels:

(Photograph taken by Joana Simões)
I must say that I still don’t feel fully comfortable with international travel in these post-COVID times, but it was a nice experience overall. Even though we all have taken great steps towards inclusivity in online conferences/workshops/events, meeting in person still feels better overall. For better or worse.
During the codesprint I explained the behaviour of my (simplistic) Leaflet client for OGC API Maps. And that organically turned into a very interesting discussion of HTTP content negotiation.
So what’s this OGC API thing, anyway?
The OGC APIs are well-defined, standardized protocols and interfaces for serving/requesting geographical information through the internet. Which means “ways of offering and getting maps (or map data)”.
We (as in “the people interested in the intersection of geography and computers”) have had these things already for years. Either in the form of de facto formats (such as “XYZ tiles” or JSON stylesheets), or well-defined protocols for a bygone era (WMS, WFS et al, which were designed in those times when CORBA and SOAP seemed like a good thing), or proprietary protocols that look open but really are not (I’m looking at you, ESRI; I’m also looking at you, Google).
The OGC APIs are still being designed and tested. They’re not going to be a cure-all panacea for geospatial data, and I’m fully sure that they won’t be able to make everybody happy. So these OGC codesprints put the potential users together, so that we all try and make these APIs palatable for all. We won’t make everybody happy, but we can try to make nobody hate the APIs.
So what’s this “HTTP content negotiation” thing, anyway?
“Content negotiation” is a part of the HTTP protocol specification. It was designed so that if a “thing” has more than one representation, “people” requesting the “thing” could choose the preferred representation.
Let’s say that the ACME corporation manufactures a gizmo, and has information about the gizmo in a URL like https://acme.corp/product/gizmo.
From that URL alone we can’t assume much. We can expect that there’s a webpage there, but from a technical standpoint there’s no guarantee. Perhaps there’s a PDF brochure. Perhaps there’s an image of the gizmo. If the URL would be https://acme.corp/product/gizmo.html we’d be more certain that it’s be a webpage; image.pdf would be a brochure, and gizmo.png would be an image. But that’s not the case here.
A webserver might have several representations for a resource - in this example, ACME corp might have a gizmo webpage, a gizmo brochure, a gizmo image, or a gizmo promotional video. And the web browser (called the “client” in protocol-speak) might prefer one representation or another.
That’s when content negotiation kicks in. The HTTP specification, in particular RFC 7231 section 5.3, provides the technical means for the web browser to say “I’d rather have this kind of representatio, please”.
So when a web browser “talks” to a web server, the HTTP communication looks something like this:
GET /product/gizmo HTTP/1.1
Accept: text/html, */*
That means “Dear webserver, I’m using version 1.1 of the HTTP protocol, and I’d like to have the resource /product/gizmo. I’d rather have it in text/html format, but if that’s not available, i’ll take anything (*/*) you can give me”.
This is a simplified example; web browsers in the real world use more complicated Accept headers, as shown in this MDN document. So more realistic example would rather look like:
GET /product/gizmo HTTP/1.1
Accept: text/html,application/xml;q=0.9,*/*;q=0.8
That q there stands for “quality”. When a format (or “media type”) doesn’t have a q value, it has an implied value of 1, meaning “this is 100% valuable to me”. A q value of 0.8 means “this is 80% as valuable as the preferred format”, and so on. Also, a wildcard (*) is less desireable than a explicit format (or “media type”). The nitty-gritty details of this are in RFC 7231 section 5.3.
So the web browser is asking the web server “I’d prefer to have text/html. If not, I’ll take application/xml but it’s only 90% as valuable to me. If not, I’ll take anything else (*/*) but that’s only 80% as valuable to me”.
The webserver can, with that information, decide what kind of representation it should reply with.
So why should OGC APIs care about content negotiation?
…because content negotiation is in the OGC API design guidelines, literally.
But I’ll be specific.
The thing that I worked on during the 19th codeprint was the default visualization of a coverage. (I still don’t know the etymology of coverage, since for me it’s a raster file, but whatever).
In an OGC API server, a coverage (or “a raster file/dataset”) will have a URL like https://my.ogcapi.server/collections/lidar2022/coverage. But there can be really different representations of it:
- A GeoTIFF file (
image/tiff) with the raw data - A NetCDF file (
application/netcdf) with the raw data - A RGB(A) image (
image/pngorimage/webp, etc) with a grayscale representation of the data - A plain text file (
text/plain) with the output of runninggdalinfoon the data - A JSON file (
text/json) containing metadata - A JSON-LD file (
application/ld+json) containing linked data - An interactive webpage (
text/html) displaying a preview of the data (when loaded in a capable web browser)
…and all of those are valid representations of a coverage dataset. Of course, they’re different representations meant for different scenarios. A human looking for readable information should have a list of priorities like Accept: text/html, text/plain;0.5, text/json;0.2 whereas a full-fledged GIS application interested in the raw data might want something like Accept: image/tiff, application/ld+json;0.7, image/webp;0.5, image/png;0.5
Which leads to my efforts during the codesprint: when pygeoapi is requested a coverage from GIS client (preferring image/tiff or application/ld+json or the like), the raw data is returned. But when it’s a web browser (preferring text/html), then a webpage with a small viewer is returned. And that webpage does a bit of client-side reprojection as well:
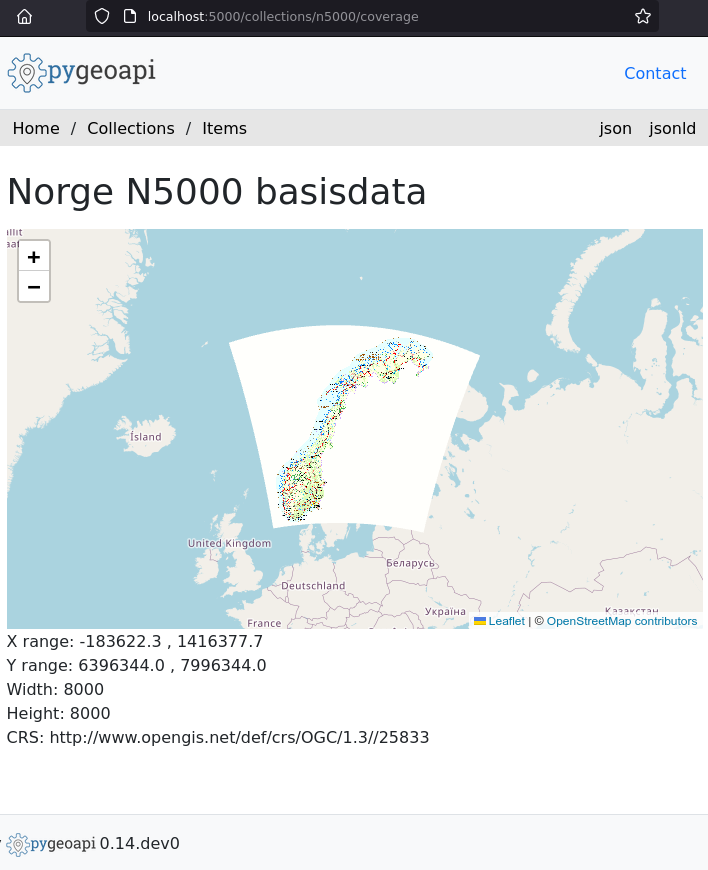
There’s still work to be done, of course (should the coverage be shown in its native projection instead of web mercator? What to do with non-RGB(A) things? etc), but the point remains: the same URL can have different representations of the data, and one of those can be an interactive webpage.
I think that, up to this point, this information is known to the people involved in designing the OGC APIs. Now I want to focus on a few things that are a bit more obscure.
So let’s pay attention to the server-side q value, starting by quoting RFC 7231 section 5.3.1, emphasis mine:
Many of the request header fields for proactive negotiation use a common parameter, named “q” (case-insensitive), to assign a relative “weight” to the preference for that associated kind of content. This weight is referred to as a “quality value” (or “qvalue”) because the same parameter name is often used within server configurations to assign a weight to the relative quality of the various representations that can be selected for a resource.
This means that an OGC API server can (and, in my opinion, should!) apply different weights to different representations.
An example: let’s suppose that the data in https://my.ogcapi.server/collections/lidar2022/coverage is stored as a NetCDF file in the server’s hard drives, and that converting from NetCDF to GeoTIFF is quite costly (in terms of CPU power). Whoever configured the server decided that fetching a NetCDF and converting it to another format is four times as expensive as just fetching the NetCDF, so the server can lower the q value of any formats different than the native one. The server can also ignore formats altogether if conversion is impossible.
So, for example:
| Format | Weight given by client | Weight factor applied by server | Final weight |
|---|---|---|---|
| image/tiff | 1 | 0.25 |
0.25 |
| application/netcdf | 0.7 | 1 | 0.7 |
| image/webp | 0.5 | N/A | N/A |
| application/ld+json | 0.4 | 0.25 | 0.1 |
Note that the “weight factors” in the above example are completely arbitrary. A server might apply different numbers as deemed fit. Or update these factors as data converted to different formats is cached; or take into account the (byte) sizes of different formats; or skip “weight factors” and use a wholly different algorithm for choosing the output format.
An interesting use case will be the image formats for RGB(A) maps or tiles. In the GIS world we’re used to the (old) problem of JPEG (or JPG) versus PNG. In a nutshell, JPEG is better for photographs and aerial images and is limited to RGB, and PNG is better for abstract graphics (such as images of lines and polygons) and supports RGBA.
Therefore, an OGC API server can be configured so that a certain collection (jargon for “thematic dataset”) would prefer RGB lossy image formats, or RGBA lossless formats.
For example, a client requesting map images for a collection representing aerial imagery (better suited for lossy compression) might be treated as…
| Format | Weight given by client | Weight factor applied by server | Final weight |
|---|---|---|---|
| image/tiff | 1 | 0.25 |
0.25 |
| application/netcdf | 0.7 | 1 | 0.7 |
| image/webp | 0.5 | 0 | 0 |
| application/ld+json | 0.4 | 0.25 | 0.1 |
That same client with that same server, but requesting images for a map render (not suited for lossy compression) might look like…
| Format | Weight given by client | Weight factor applied by server | Final weight |
|---|---|---|---|
| image/tiff | 1 | 0.25 |
0.25 |
| application/netcdf | 0.7 | 1 | 0.7 |
| image/webp | 0.5 | 0 | 0 |
| application/ld+json | 0.4 | 0.25 | 0.1 |
And a situation with the same client and server, but imagery with more than four colour channels might look like…
| Format | Weight given by client | Weight factor applied by server | Final weight |
|---|---|---|---|
| image/tiff | 0.3 | 1 |
0.3 |
| image/jxl | 0.7 | 1 | 0.7 |
| image/webp | 1 | 0.2 | 0.2 |
| image/png | 0.9 | 0.2 | 0.18 |
(Again, as a reminder: all those values in the examples are arbitrary)
Unfortunately, relying on content negotiation can have a big disadvantage: difficulties to cache the data. A naïve caching layer will cache on a per-URL basis, rendering content negotiation unavailable. A less-naïve caching layer can store the full Accept header to prevent this, but that risks duplicating cached information. I’m not sure what’s the best approach here. Maybe the answer lies in using HTTP 301 redirects?
I think content negotiation still deserves some more attention from the OGC API implementations: using the capabilities of the HTTP protocol can render some undiscovered benefits here, and there’s a general desire to make this work with the existing web infrastructure (browsers, caches, etc).
I’m assuming that there’ll be OGC API clients that are not web browsers, and that they will use their own format preferences. For fine-tuning image format preferences in web browsers, we can leverage the <picture> and <source> HTML elements nowadays (but that’s kinda out of the scope of this writing).
On a related note, modern image formats (WebP, JPEG XL and AVIF) can replace the good old JPEG and PNG with few or no downsides, and OGC API server implementations should offer the former when possible.
So, in short:
- OGC API clients can use
Acceptheaders for content negotiation. - This means that the client can specify data formats in an order of preference.
- The OGC API server can then apply different rules to modify that order of preference:
- Is the data readily available, or is it costly to have in that format?
- Can the format accommodate the data? (colour channels, etc)
- Does the data suffer a quality lowering in any format(s)?
- Caching algorithms can be difficult
- Contemporary image formats are nice
I do hope to be able to explore these topics in the future.